M1 GPUs for C++ science: accelerating PDEs
Relevant preprint, previous post.
You might have read the two previous posts detailing benchmarks for array operations on the M1 GPU. We extended this work a bit to simulating partial differential equations for e.g. tomographic imaging. The original abstract for this work is given below, but to get the full read, head over to arXiv! A peer-reviewed version of this manuscript is in the works.
Original abstract
The M1 series of chips produced by Apple have proven a capable and power-efficient alternative to mainstream Intel and AMD x86 processors for everyday tasks. Additionally, the unified design integrating the central processing and graphics processing unit, have allowed these M1 chips to excel at many tasks with heavy graphical requirements without the need for a discrete graphical processing unit (GPU), and in some cases even outperforming discrete GPUs.
In this work, we show how the M1 chips can be leveraged using the Metal Shading Language (MSL) to accelerate typical array operations in C++. More importantly, we show how the usage of MSL avoids the typical complexity of CUDA or OpenACC memory management, by allowing the central processing unit (CPU) and GPU to work in unified memory. We demonstrate how performant the M1 chips are on standard 1D and 2D array operations such as array addition, SAXPY and finite difference stencils, with respect to serial and OpenMP accelerated CPU code. The reduced complexity of implementing MSL also allows us to accelerate an existing elastic wave equation solver (originally based on OpenMP accelerated C++) using MSL, with minimal effort, while retaining all CPU and OpenMP functionality.
The resulting performance gain of simulating the wave equation is near an order of magnitude for specific settings. This gain attained from using MSL is similar to other GPU-accelerated wave-propagation codes with respect to their CPU variants, but does not come at much increased programming complexity that prohibits the typical scientific programmer to leverage these accelerators. This result shows how unified processing units can be a valuable tool to seismologists and computational scientists in general, lowering the bar to writing performant codes that leverage modern GPUs.
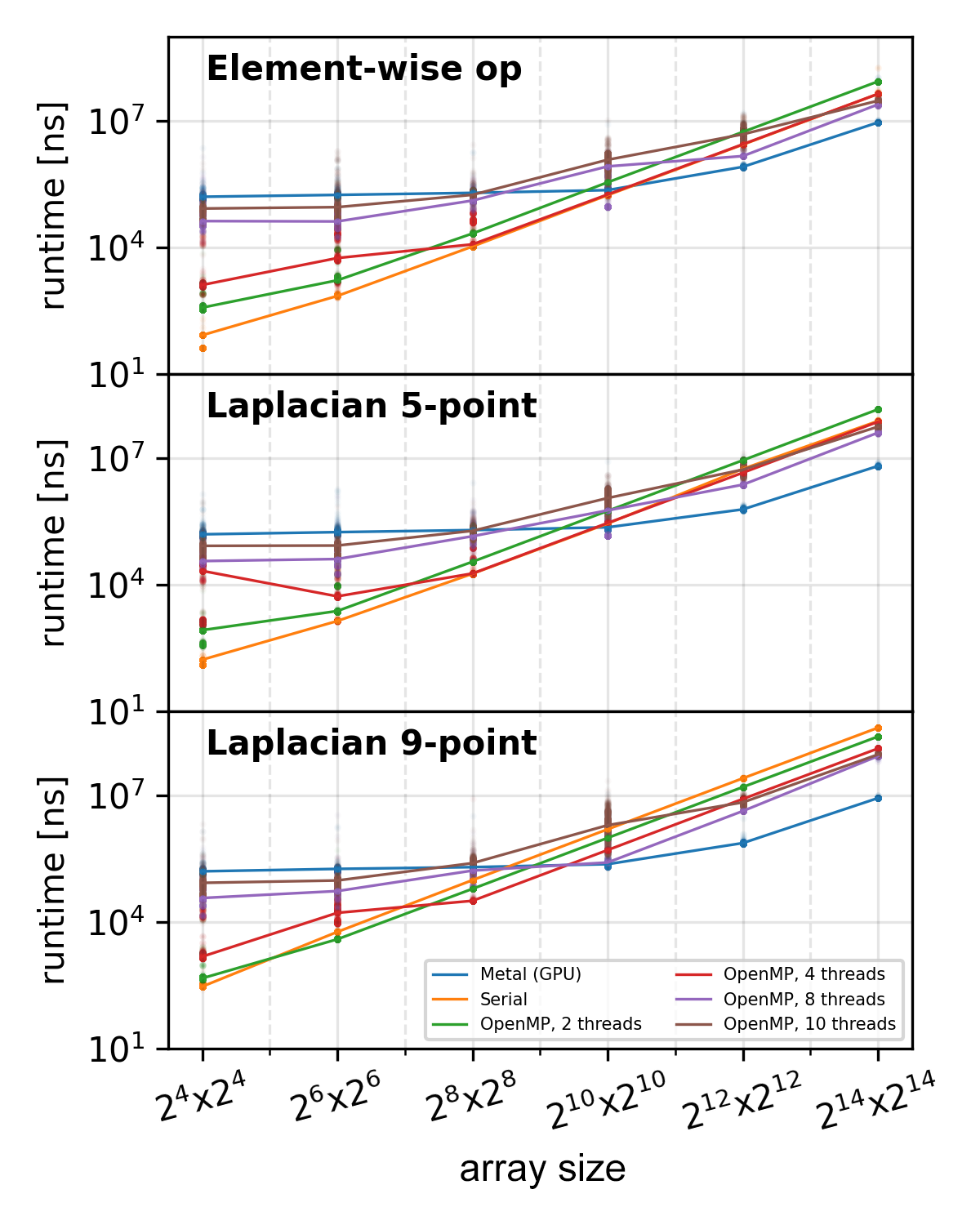
Demo results
The figure below, taken from the preprint, is an example of how MSL can speed up array operations of large enough size considerably. Especially at large sizes, the speed-up nears an order of magnitude.